

تعتبر كيفية الاستعانة بالذكاء الاصطناعي في تشخيص الأمراض واحدة من أكثر المواضيع إثارة في مجال الطب الحديث، حيث تعيد تشكيل الطريقة التي نتعامل بها مع الرعاية الصحية. في عصر تتزايد فيه تعقيدات الأمراض واحتياجات المرضى، يتيح الذكاء الاصطناعي للأطباء أدوات متقدمة لتحليل البيانات الطبية بسرعة ودقة غير مسبوقتين. من خلال استخدام خوارزميات التعلم العميق وتحليل الصور الطبية، كما يمكن للذكاء الاصطناعي أن يساعد في الكشف المبكر عن الأمراض مثل السرطان وأمراض القلب، مما يسهم في إنقاذ الأرواح وتحسين النتائج الصحية. في هذا المقال، سنستعرض كيفية استخدام هذه التكنولوجيا الثورية، والتحديات التي تواجهها، وآفاق المستقبل في عالم الطب. دعونا نبدأ رحلة استكشاف كيف يمكن للذكاء الاصطناعي أن يحدث ثورة في تشخيص الأمراض ويغير وجه الرعاية الصحية كما نعرفها.
جدول المحتويات
- المقدمة
- تشخيص الامراض
- ما هو الذكاء الاصطناعي والتعلم الآلي؟
- أنواع البيانات للتعلم الآلي والذكاء الاصطناعي
- تقنيات الذكاء الاصطناعي في تشخيص الأمراض والتنبؤ بها
- تطبيقات تقنيات اخرى في تشخيص الامراض
- الكشف عن الأمراض باستخدام معالجة اللغة الطبيعية
- تشخيص أمراض الأوعية الدموية
- الدور المحوري للذكاء الاصطناعي في تشخيص الأمراض البشرية والتنبؤ بها
- التحديات والتوجهات المستقبلية في الذكاء الاصطناعي والرعاية الصحية
المقدمة
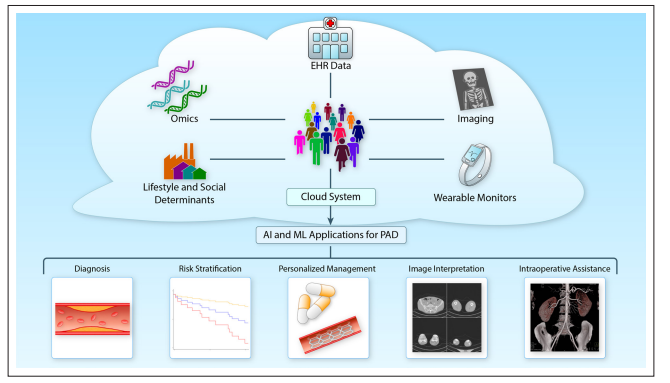
سعت العديد من التخصصات الطبية إلى الاستفادة من “البيانات الضخمة” والتحليلات المتقدمة، إلا أن التكامل العملي لأنظمة الذكاء الاصطناعي والطب لا يزال في مراحله الأولى. عند تطبيقها على مرض الشرايين المحيطية، كما تعد التحليلات المتقدمة بتحديد الأمراض الكامنة، وتحسين النمط الظاهري للمرض والمخاطر، ومساعدة خيارات العلاج مع مراعاة النطاق الكامل للبيانات الديموغرافية والبيولوجية والسريرية (الشكل 1).
كما ستوفر أدوات التصوير الوعائي القائمة على الذكاء الاصطناعي (AI) الدعم للإعدادات التشخيصية والتنبؤية وأثناء الجراحة. نظراً لتشتت رعاية أمراض الشرايين المحيطية (PAD) في كثير من الأحيان عبر مواقع وتخصصات مختلفة، يمكن للذكاء الاصطناعي أيضاً المساعدة في دمج نقاط بيانات الرعاية، مما يعزز الرعاية الشاملة متعددة التخصصات التي تُعدّ بالغة الأهمية لتحسين الإدارة والنتائج.
تشخيص الامراض
تعد الرعاية الصحية البشرية من أهم المواضيع في المجتمع. يسعى هذا البحث إلى إيجاد الكشف الصحيح والفعال والفعال عن الأمراض بأسرع وقت ممكن، بما يضمن حصول المرضى على الرعاية المناسبة. ولأن هذا الكشف غالبًا ما يكون مهمة صعبة، فإنه يتطلب دعمًا من مجالات أخرى، مثل الإحصاء وعلوم الحاسوب، في مجال البحث الطبي. كما تواجه هذه التخصصات تحديًا يتمثل في استكشاف تقنيات جديدة تتجاوز التقنيات التقليدية. ويتطلب العدد الكبير من التقنيات الناشئة تقديم نظرة شاملة تتجنب الجوانب الخاصة.
ولتحقيق ذلك، نقترح مراجعة منهجية تتناول تطبيق التعلم الآلي في تشخيص الأمراض البشرية. كما تركز هذه المراجعة على التقنيات الحديثة المتعلقة بتطوير التعلم الآلي في المجال الطبي، بهدف اكتشاف أنماط مثيرة للاهتمام، وتقديم تنبؤات عملية ومفيدة في صنع القرار. وبهذه الطريقة، كما يمكن أن يساعد هذا العمل الباحثين على اكتشاف، وتحديد مدى قابلية تطبيق تقنيات التعلم الآلي في تخصصاتهم، عند الحاجة.
تعريف تشخيص الأمراض
تعد الرعاية الصحية من أكثر الأمور إلحاحًا في المجتمعات البشرية، إذ تعتمد جودة حياة المواطنين عليها بشكل مباشر . ومع ذلك، يتسم قطاع الرعاية الصحية بتنوعه الشديد وانتشاره الواسع وتجزؤه. من المنظور السريري، يتطلب تقديم الرعاية المناسبة للمرضى الوصول إلى معلومات المريض ذات الصلة، والتي نادرًا ما تكون متاحة أينما ومتى دعت الحاجة إليها. بالإضافة إلى ذلك، يشير التباين الكبير في طلب الاختبارات لأغراض التشخيص إلى ضرورة وجود مجموعة اختبارات كافية ومناسبة .
وقد وسّع العلماء والباحثين هذه الحجة من خلال الإشارة إلى أن الاختلافات الكبيرة الملحوظة في طلب علم الأمراض في الممارسة العامة تنتج في الغالب عن التباين الفردي في الممارسة السريرية، وبالتالي فهي عرضة للتغيير من خلال اتخاذ قرارات أكثر اتساقًا واستنارة للأطباء. وبالتالي، غالبًا ما تتكون البيانات الطبية من مجموعة كبيرة من المتغيرات غير المتجانسة، التي يتم جمعها من مصادر مختلفة، مثل التركيبة السكانية، وتاريخ المرض، والأدوية، والحساسية، والعلامات الحيوية، والصور الطبية، أو العلامات الجينية، حيث يقدم كل منها رؤية جزئية مختلفة عن حالة المريض.
ما هو الذكاء الاصطناعي والتعلم الآلي؟
الذكاء الاصطناعي (AI) يعرف بأنه استخدام خوارزميات الحاسوب لأتمتة مهام محددة، بهدف تقليد عمليات التفكير والتعلم البشرية. ومن الأمثلة البارزة على ذلك المساعدات الرقمية مثلا “سيري” من أبل و”أليكسا” من أمازون، حيث تستفيد هذه الأنظمة من تقنيات الذكاء الاصطناعي لفهم الكلام وتفسيره والاستجابة له بطريقة تشبه ردود الفعل البشرية. ومع مرور الوقت، “تتعلم” هذه المساعدات الرقمية وتتكيف، مما يعزز دقة استجابتها.
في صميم الذكاء الاصطناعي نجد التعلم الآلي (ML)، الذي يعد فرعًا من الذكاء الاصطناعي يعتمد على الخوارزميات الحسابية. تمكّن خوارزميات التعلم الآلي من أتمتة المهام من خلال التعلم من البيانات. ويوجد العديد من أنواع خوارزميات التعلم الآلي، والتي تصنف عمومًا بناءً على كيفية “تعلمها”. في سياق التعلم الآلي، ينطوي التعلم على تطبيق صيغ رياضية على البيانات، مما يسمح بتلخيص العلاقات بين الخصائص (أو المتغيرات) رياضيًا. والنتيجة النهائية لهذه العملية هي نموذج يمثل هذه العلاقات الرياضية، والذي يمكن استخدامه لاحقًا للتنبؤ بالقيم المتوقعة أو تصنيف النتائج، مثل تحديد نتائج المختبر أو حالات المرضى.
في التعلم المراقب، يتم تدريب الخوارزميات على بيانات تحتوي على نتائج أو تصنيفات (مثل وجود المرض) معروفة مسبقًا، مما يوفر للخوارزمية حقائق مؤكدة. في المقابل، يتضمن التعلم غير المراقب بيانات بدون نتائج مصنفة، مما يسمح للخوارزمية بالكشف عن الأنماط والهياكل بشكل مستقل.
لتوضيح ذلك بشكل أكبر، تلخص الجدول 1 مختلف خوارزميات التعلم الآلي وفقًا لطرق التعلم المستخدمة، بينما يسرد الجدول 2 المصطلحات الأساسية اللازمة لفهم تطوير نماذج التعلم الآلي.
جدول (1) أنواع خوارزميات التعلم الآلي
| نوع خوارزمية ML | التعريف |
|---|---|
| التعلم المراقب | تعلم يعتمد على مجموعة من الأمثلة المحددة للتنبؤ أو التصنيف في حالة معينة. |
| Random Forest | مجموعة من أشجار القرار التي تُستخدم للتنبؤ أو التصنيف، حيث يتم دمج النتائج من عدة أشجار لتحسين الدقة. |
| Support Vector Machine (SVM) | نموذج يستخدم للانحدار والتصنيف، حيث يقوم بفصل البيانات بواسطة خط أو مستوى، مما يساعد في تحديد الفئات المختلفة. |
| Unsupervised Learning | التعلم الذي لا يعتمد على نتائج مسبقة، حيث تُستخدم البيانات لاكتشاف الأنماط. |
| Clustering | تقنية تستخدم لتجميع البيانات المتشابهة في مجموعات، مما يساعد على التعرف على الأنماط. |
| Dimensionality Reduction | تقنيات لتقليل عدد المتغيرات في البيانات مع الحفاظ على المعلومات المهمة. |
| Natural Language Processing (NLP) | تقنية تهدف إلى تمكين الحواسيب من فهم اللغة البشرية والتفاعل معها. |
| Reinforcement Learning | نموذج تعلم يعتمد على التفاعل مع البيئة واكتساب المكافآت من خلال التجربة، مما يساعد على تحسين الأداء بمرور الوقت. |
| Transfer Learning | استخدام نموذج تم تدريبه مسبقًا على مهمة معينة لتسريع عملية التدريب على مهمة جديدة. |
جدول (2) المصطلحات الأساسية لتطوير نماذج التعلم الآلي
| المصطلح | التعريف |
|---|---|
| Features | المتغيرات المأخوذة من مجموعة بيانات تُستخدم لتدريب النموذج. |
| Training Dataset | مجموعة البيانات المستخدمة لتعديل النموذج وتحديد معاييره التعليمية. |
| Validation Dataset | مجموعة بيانات تُستخدم لتقييم أداء النموذج أثناء التدريب، مما يساعد في تحسين المعايير. |
| Test Dataset | مجموعة بيانات تُستخدم لتقييم أداء النموذج النهائي، مستقلة عن مجموعة التدريب. |
| Overfitting | حالة يتم فيها تخصيص النموذج بشكل مفرط لمجموعة التدريب، مما يؤثر سلبًا على الأداء العام. |
| Cross-Validation | تقنيات تستخدم لتقييم النموذج عن طريق تقسيم البيانات إلى مجموعات فرعية وتدريبها بشكل متكرر. |
| Bootstrapping | تقنية إعادة أخذ العينات تُستخدم لتقدير الأخطاء أو تحسين التدريب من خلال إنشاء مجموعات فرعية. |
أنواع البيانات للتعلم الآلي والذكاء الاصطناعي
تعدّ قواعد البيانات الصحية الضخمة جزءًا لا يتجزأ من تطوير ونشر مناهج الذكاء الاصطناعي والتعلم الآلي. ومع اعتماد أنظمة السجلات الصحية الإلكترونية. أصبح من الشائع جمع أنواع متعددة من البيانات من مريض الأوعية الدموية على مدار سنوات عديدة. كما تشمل هذه البيانات الملاحظات السريرية، والبيانات الإدارية، وصور الأشعة والمختبرات الوعائية والتقارير المرتبطة بها، والقياسات الفيزيائية والمخبرية.
ولا يقتصر تراكم البيانات الهائلة على بيئة الرعاية الصحية فحسب. بل يشمل أيضًا الدراسات الجينية واسعة النطاق والأجهزة الاستهلاكية، مثل الأجهزة القابلة للارتداء والهواتف الذكية، التي قد تسهم في توفير بيانات فسيولوجية وسلوكية. علاوة على ذلك، ظهر عدد من البنوك الحيوية التي تربط بيانات السجلات الصحية الإلكترونية الطولية بالبيانات الجينية التكميلية والاستبيانات التي تميّز نمط الحياة والعوامل البيئية.
تقنيات الذكاء الاصطناعي في تشخيص الأمراض والتنبؤ بها
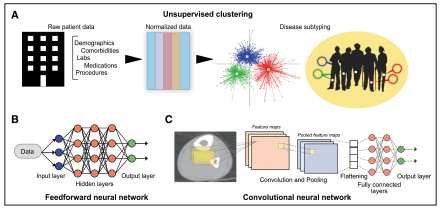
يهدف الذكاء الاصطناعي (AI)، وهو مجال واسع يجمع بين الرياضيات والعلوم، إلى تمكين الآلات من أداء مهام “ذكية” تلقائيًا. يُعد التعلم الآلي فرعًا أساسيًا من الذكاء الاصطناعي، يضم الشبكات العصبية والتعلم العميق. كما يهدف التعلم الآلي إلى تدريب الآلات على تحليل مجموعات البيانات واكتساب الخبرة لتحسين دقتها في المهام المحددة والعمل بفاعلية على البيانات الجديدة.
في المجال الطبي، أحدث الذكاء الاصطناعي، خاصة التعلم العميق، ثورة في التشخيص الآلي للتصوير الطبي. مما قلل من الأخطاء البشرية الناتجة عن نقص الدقة أو الخبرة. يلعب الذكاء الاصطناعي دورًا حاسمًا في تصنيف الأمراض المعتمد على الصور، والتشخيص بمساعدة الحاسوب (CAD)، وتجزئة أمراض الصور. نظرًا لتعقيد محاكاة صور الأنسجة والأعضاء، تعتمد مهام التشخيص على عملية التدريب. كما يساهم الذكاء الاصطناعي في جمع ومعالجة البيانات الطبية وتحسين رعاية المرضى، وحتى برمجة الروبوتات الجراحية. مما يعكس قدرة الآلة على التعلم من خلال التعرف على الأنماط في المواقف المعقدة.
تطبيق التعلم الآلي في تشخيص الأمراض القائمة على الصور
يعد التعلم الآلي (ML) مجالًا فرعيًا واعدًا للذكاء الاصطناعي. يكتسب أهمية متزايدة في تحليل التصوير الطبي وتشخيص الأمراض القائمة على الصور. مع التطورات المستمرة في تقنيات التصوير الطبي مثل التصوير المقطعي المحوسب (CT) والرنين المغناطيسي (MRI). كما تزداد الحاجة إلى أساليب تعلم آلي متقدمة لتحليل هذه البيانات المعقدة.
يتميز التعلم الآلي بكونه مدفوعًا بالبيانات، حيث يقوم البرنامج بتحليل بيانات التدريب للكشف التلقائي عن الأنماط واستخدامها للتنبؤ أو اتخاذ القرارات بحد أدنى من التدخل البشري. كذلك قد تم تطبيق العديد من التقنيات الحديثة في هذا المجال لتشخيص الأمراض، منها:
- معالجة اللغة الطبيعية (NLP): تستخدم لتحليل السجلات الصحية الإلكترونية (EHRs) واستخلاص المعلومات المفيدة للتنبؤ بالأمراض.
- الذكاء الاصطناعي القابل للتفسير (Explainable AI): مثل تقنية SHAP، توفر هذه التقنيات تفسيرات للتنبؤات التي تقدمها نماذج التعلم الآلي، مما يضمن الشفافية في اتخاذ القرارات الطبية.
- النماذج التوليدية (Generative Models): مثل شبكات الخصومة التوليدية (GANs)، التي يمكنها توليد صور طبية اصطناعية لزيادة مجموعات البيانات الحالية وتحسين أداء النماذج.
يمكن دمج هذه التقنيات لتعزيز أداء النماذج، ويعتمد اختيار التقنية الأنسب على نوع البيانات وطبيعة المشكلة الطبية المحددة.
تطبيقات التعلم العميق في تشخيص الأمراض القائمة على الصور
يعد التعلم العميق (DL) تقنية بالغة القوة، قادرة على التعلم التلقائي للعديد من السمات والأنماط، مما يجعلها من أقوى التقنيات. لقد أتاح التعلم العميق بناء نماذج تنبؤية للتشخيص المبكر للأمراض. ونظرًا لاستخدام العلماء لأساليب تحليل الأنماط المثبتة. فإن خوارزميات التعلم العميق تتفوق على أساليب التعلم الآلي التقليدية بفضل نتائجها عالية الدقة، واستخلاص السمات التلقائي، وقدرتها على تحليل البيانات الضخمة. وعند التعامل مع البيانات الكبيرة، تظهر نتائج استخدام خوارزميات التعلم العميق تفوقًا واضحًا على التعلم الآلي. علاوة على ذلك، غالبًا ما يتجاوز الأداء التنبؤي للتعلم العميق قدرات البشر، مما يجعله الطريقة المفضلة للتعامل مع الصور.
لقد حظي التعلم العميق بتقدير استثنائي في المجال الطبي فيما يتعلق بمعالجة الصور. حيث يركز التشخيص بشكل أساسي على استخلاص المعلومات المفيدة من الصور. كما في تشخيص الأمراض القائم على الصور الطبية، تتنوع خوارزميات التعلم العميق بشكل أساسي، وتشمل:
- الشبكات العصبية التلافيفية (CNN)
- الشبكات العصبية العميقة (DNN)
- شبكة الاعتقاد العميق (DBN)
- المشفرات التلقائية العميقة (Deep Automatic Encoder)
- آلة بولتزمان العميقة (DBM)
- التعلم الآلي المكثف العميق العادي (DC-ELM)
- الشبكة العصبية المتكررة (RNN) وأنواعها مثل BLSTM و MDLATM.
تطبيقات تقنيات اخرى في تشخيص الامراض
- شبكة الالتفاف البياني لتجميع المناطق (RAGCN):
- هي تقنية للتعلم العميق لتحليل البيانات الطبية تستخدم شبكات الالتفاف البياني (GCNs) لتجميع المعلومات من مناطق مختلفة من الصورة. وهي مصممة خصيصًا للصور الطبية، مثل فحوصات CT و MRI، والتي غالبًا ما تحتوي على مناطق متعددة ذات أهمية (ROIs) تحتاج إلى تحليل منفصل.
- تستخدم RAGCN نهجًا قائمًا على الرسم البياني لتقسيم الصورة إلى مناطق مختلفة ثم تطبيق GCNs على كل جزء لاستخراج السمات وتقديم التنبؤات. على سبيل المثال، تم تقديم طريقة تقدير تلقائي لعمر العظام باستخدام CNN و GCN، حيث تم استخدام CNN و GCN لاستخراج السمات واستدلال مناطق العظام الرئيسية على التوالي. من خلال الجمع بين هذين النوعين من الشبكات، تمكنوا من تصميم GCN جديد (RAGCN) يمكنه التحقق من سمات المنطقة في تقييم عمر العظام.
- شبكة الهرم لتركيز الآفة (LAPNet):
- هي طريقة أخرى للتعلم العميق للبيانات الطبية مصممة للكشف عن الآفات وتصنيفها في الصور الطبية. تستخدم LAPNet بنية قائمة على الهرم لاستخراج السمات من الصورة بمقاييس مختلفة.
- كما تستخدم آلية انتباه للتركيز على مناطق معينة من الصورة التي من المحتمل أن تحتوي على آفات؛ وقد استخدم المؤلفون هذه التقنية لتصنيف اعتلال الشبكية السكري. لقد قاموا بتدريب LAPNet على مجموعة بيانات كبيرة من الصور الطبية لتعلم الكشف عن مناطق الآفة.
الكشف عن الأمراض باستخدام معالجة اللغة الطبيعية
نظرًا للكم الهائل من البيانات النصية في السجلات الصحية الإلكترونية، تم تحليل أساليب معالجة اللغة الطبيعية (NLP) كأداة فعالة لتحديد حالات أمراض الشرايين المحيطية. على سبيل المثال، استخدمت شركة “أفضال العال” خوارزمية NLP قائمة على القواعد لتحليل ملاحظات مستودع بيانات مايو كلينيك، بهدف أتمتة عملية حذف أمراض الشرايين المحيطية الشائعة. تم بناء نموذج NLP باستخدام كلمات مفتاحية مرتبطة بحالات هذه الأمراض، مما ساعد في تحسين دقة الكشف عن المرض.
عند تحليل 300-364 عينة، أظهر نموذج NLP دقة أعلى في تحديد حالات اعتلال الشرايين المحيطية، حيث بلغت دقته 92% مقارنة بـ 82% للطُرق التقليدية. كما حقق النموذج قيمة تقديرية إيجابية أعلى، مما يدل على فعاليته في تقليل النتائج الإيجابية الخاطئة. بالإضافة إلى ذلك، ثبتت خوارزميات NLP تفوقها في تصنيف المرضى الذين يعانون من نقص تروية الأطراف الحرج.
في سياق مشابه، استفاد فايسلر وزملاؤه من منهجية NLP لتحديد مرضى اعتلال الشرايين المحيطية باستخدام ملاحظات من جميع اللقاءات السريرية. بدلاً من الاعتماد على خوارزميات قائمة على القواعد، تم تدريب نموذج NLP باستخدام تقنية الانتباه الهرمي، مما زاد من دقة التصنيف. كذلك أظهرت النتائج تفوق نموذج NLP على الأساليب التقليدية، حيث سجلت AUC قدره 0.888 مقارنةً بـ 0.801. مما يبرز أهمية استخدام الذكاء الاصطناعي في تحسين رعاية المرضى.
تشخيص أمراض الأوعية الدموية
الكشف عن الأمراض باستخدام أساليب التعلم الخاضع للإشراف:
- تمكن نماذج التعلم الآلي (ML) الكشف الآلي عن الأمراض. وقد أجريت دراسة في عام 2016 لاستخدام التعلم الآلي لتحديد مرض الشريان المحيطي (PAD) غير المشخص.
- أظهرت الدراسة أن 17% من المرضى يعانون من مرض الشريان المحيطي. وأن 68% منهم لم يتم تشخيصهم عند تسجيلهم في الدراسة، مما يؤكد أن مرض الشريان المحيطي غير معترف به بشكل كافٍ.
- تم تطوير نموذج تصنيف لتحديد حالات مرضى الشريان المحيطي غير المشخصين سابقًا، باستخدام متغيرات بيانات متنوعة. تشمل التركيبة السكانية، التاريخ الطبي، العوامل الوراثية، ونتائج تصوير الأوعية التاجية.
- استند نموذج التنبؤ بمرض الشريان المحيطي الأكثر دقة إلى خوارزمية الغابات العشوائية (random forest algorithm). وقد تضمن النموذج النهائي أكثر من 120 خاصية أساسية.
الدور المحوري للذكاء الاصطناعي في تشخيص الأمراض البشرية والتنبؤ بها
يحدث الذكاء الاصطناعي (AI) ثورة في الرعاية الصحية بقدرته على تحليل البيانات الطبية المعقدة، مثل صور الأشعة والسجلات الصحية، لتقديم تشخيصات مبكرة ودقيقة للأمراض والتنبؤ بها. كما تعتمد هذه التقنيات على خوارزميات التعلم الآلي والتعلم العميق، التي تتعلم من كميات هائلة من البيانات لتحسين دقتها باستمرار. وغالبًا ما تتفوق على القدرة البشرية في تحليل الصور والأنماط المعقدة.
تطبيقات الذكاء الاصطناعي في مجالات طبية رئيسية:
أمراض القلب
يسهم الذكاء الاصطناعي بشكل كبير في تشخيص أمراض القلب، مثل مرض الشريان التاجي التصلبي. فتقنيات مثل CT-FFR القائمة على التعلم الآلي والعميق تُبسط وتسارع عملية التشخيص، مما يسمح بالكشف المبكر والعلاج الفعال. أظهرت نماذج مثل SVM و ANN دقة عالية في تحديد أمراض القلب المختلفة، تتجاوز 89% في بعض الحالات.
أمراض الدماغ
غيّر الذكاء الاصطناعي من تشخيص أمراض الدماغ والتنكس العصبي كـالزهايمر وباركنسون وأورام الدماغ، التي يصعب اكتشافها مبكرًا. تُمكن هذه التقنيات من تحليل كميات هائلة من إشارات الدماغ وبياناته، كشفًا عن رؤى وعلاقات لا تُرى بالعين المجردة. حققت نماذج CNN وتركيبات خوارزمية مثل الخوارزمية الجينية والغابات العشوائية دقة تصل إلى 95.58% في تشخيص مرض باركنسون.
سرطان الثدي
يلعب الذكاء الاصطناعي دورًا حيويًا في الكشف المبكر عن سرطان الثدي، وهو عامل حاسم في نجاح العلاج. باستخدام مجموعات بيانات مثل WBCD. حققت خوارزميات مثل LSSVM و SVM بالاقتران مع اختيار الميزات، دقة تصنيف عالية جدًا، وصلت إلى 99.51% في بعض الدراسات. كما أظهرت طرق دمج المصنفات نتائج ممتازة في التمييز بين الأورام الحميدة والخبيثة.
الاضطرابات الوراثية
يساعد الذكاء الاصطناعي في التنبؤ وتصنيف الاضطرابات الوراثية من البيانات الجينية المعقدة، رغم التحديات مثل حجم العينات المحدود. على سبيل المثال، حقق نموذج قائم على ANN دقة تزيد عن 85% في مراحل التدريب والاختبار، وأظهرت الشبكات العصبية متعددة الطبقات (MLP) دقة 100% في بعض دراسات اضطراب طيف التوحد (ASD).
الأمراض الجلدية
للذكاء الاصطناعي تطبيقات واسعة في طب الأمراض الجلدية، حيث يمكن تدريب نماذج التعلم الآلي والتعلم العميق لتشخيص وتصنيف أمراض الجلد المختلفة، بما في ذلك سرطان الجلد. تساعد هذه الأنظمة الأطباء في الكشف المبكر والدقيق، خاصة في حالات نقص الخبرة، مما ينقذ الأرواح ويقلل التكاليف. حققت طرق التعلم العميق دقة تتجاوز 91% في التنبؤ وتصنيف آفات سرطان الجلد.
سرطان البروستاتا
عزز الذكاء الاصطناعي دقة تشخيص سرطان البروستاتا والتنبؤ باستجابة المريض للعلاج الإشعاعي ومعدلات البقاء على قيد الحياة. كذلك ان نماذج التعلم الآلي القائمة على صور الرنين المغناطيسي (MRI) ونهج التعلم العميق مثل XmasNet، كذلك أظهرت دقة عالية في تصنيف آفات سرطان البروستاتا، متفوقة على الطرق التقليدية.
سرطان الرئة والتهابات الجهاز التنفسي
ساهم الذكاء الاصطناعي بشكل كبير في الكشف المبكر عن سرطان الرئة باستخدام صور الأشعة المقطعية (CT) والأشعة السينية. أظهرت نماذج CNN و DCNN فعالية عالية في تصنيف أنواع سرطان الرئة المختلفة. كما تُستخدم نماذج التعلم العميق بنجاح في تحليل بيانات الجهاز التنفسي وتشخيص أمراض الرئة مثل مرض الانسداد الرئوي المزمن (COPD) وكوفيد-19، بدقة تصل إلى 95.7%.
التحديات والتوجهات المستقبلية في الذكاء الاصطناعي والرعاية الصحية
تتطلب الأنظمة المعتمدة على الذكاء الاصطناعي بيانات متنوعة وتمثيلية لتكون فعالة. إلا أن قضايا توافق البيانات بين أنظمة السجلات الصحية الإلكترونية تمثل تحديًا كبيرًا. تتطلب نماذج التوحيد القياسي للبيانات تبنيًا أكبر لتعزيز تبادل البيانات وتطوير أدوات الذكاء الاصطناعي بشكل عادل. كما أن التحيزات في البيانات تعتبر قضية هامة، حيث يمكن أن تؤدي البيانات غير الممثلة إلى نتائج تمييزية في تقديم الرعاية الصحية.
تعد خصوصية المرضى أيضًا نقطة حساسة، حيث يتطلب استخدام البيانات من مؤسسات متعددة اتخاذ تدابير أمنية قوية لحماية المعلومات الشخصية. كما ان تقنيات مثل التعلم الفيدرالي تعتبر حلولًا واعدة لتحسين الخصوصية.
أخيرًا، يجب أن تتضمن عملية تنفيذ أدوات الذكاء الاصطناعي تعاونًا مبكرًا بين العلماء والمتخصصين في الرعاية الصحية لضمان تصميم واجهات سهلة الاستخدام تلبي احتياجات الأطباء والمرضى، مما يسهل دمج هذه التقنيات في الممارسات السريرية.


